デジタルマーケ・AI研修における「【G検定対応講座(3)】機械学習の概要」のコース概要
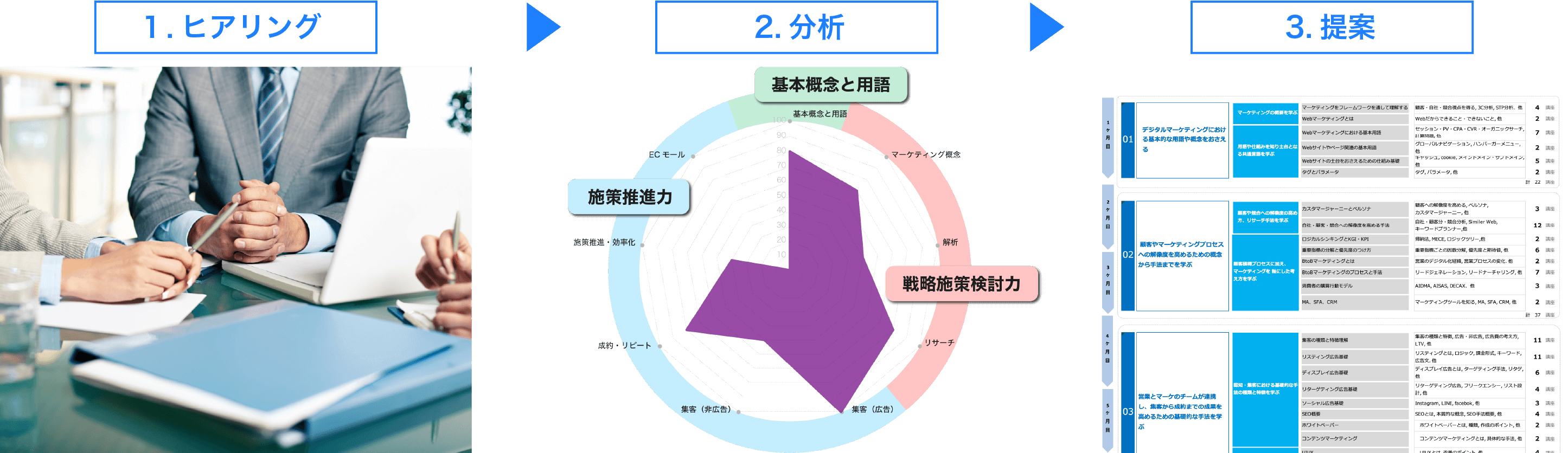
コースの概要
機械学習のしくみを、実践的に理解する
このコースでは、AIの中核をなす「機械学習」について、基本的な考え方から応用までをバランスよく学んでいきます。モデルをどう作り、どう選び、どう評価するか——実務に活かせる視点で、機械学習の全体像がつかめる内容です。
最初は、予測や分類に使われるしくみを中心に、機械学習の入り口となる考え方に触れます。モデルがデータからどう学ぶのかを理解すると、技術がぐっと身近に感じられるはずです。
次に、複数のモデルを組み合わせて精度を高める方法や、より柔軟な判断を可能にするアルゴリズムの工夫も扱います。ここでは、複雑な仕組みも文脈の中で少しずつ見えてくるように解説していきます。
「データをグループに分ける」や「必要な情報だけを抽出する」といった操作も、実際によく使われるものです。そうした処理を通じて、データの構造や特徴を見抜く力を身につけていきます。
また、ユーザーに合ったおすすめを提示するしくみや、AIが報酬を得ながら学んでいくタイプの学習法にも触れます。いずれも、今のサービスや製品の裏側を知るヒントになるでしょう。
最後に、モデルの良し悪しを見極めるための評価の考え方や、複雑すぎるモデルを避ける視点なども紹介します。技術をただ使うだけでなく、選ぶ力も同時に鍛えていきます。
難しそうに見えても、一つひとつのテーマは日々の仕事や暮らしにもつながる考え方ばかり。ここで学んだ知識が、AIをもっと自然に使いこなすための土台になってくれるはずです。

コース詳細
<01>教師あり学習の基本問題
この授業では演習問題を通して教師あり学習の概要を学びます。
教師あり学習は、データに正解ラベルを与えて学習する手法であり、大きく回帰問題と分類問題に分かれます。回帰問題では、数値を予測するタスク(例:気温予測、売上予測)が中心で、代表的な手法に線形回帰や重回帰分析があります。一方、分類問題ではデータをカテゴリに分類するタスク(例:迷惑メール判定、画像分類)があり、ロジスティック回帰やサポートベクターマシン(SVM)がよく使用されます。また、自己回帰モデル(AR)は時系列データを扱うモデルであり、単一の時系列データを用いることが特徴です。本授業では、教師あり学習の手法とその適用例について詳しく学びます。
<02>アンサンブル学習と関連手法
この授業では演習問題を通してアンサンブル学習を学びます。
アンサンブル学習は、複数のモデルを組み合わせることで予測精度を向上させる手法です。本授業では、その概要と実用的な活用方法について学びます。
<03>高度な手法と特徴的なアルゴリズム
この授業では演習問題を通してサポートベクターマシン(SVM)を学びます。
SVMは分類問題を解くための機械学習手法の一つで、特に2クラス分類に適用されます。本授業では、SVMの特徴であるマージン最大化や、非線形データを扱うためのカーネルトリックについて学び、その応用方法を理解します。
<04>クラスタリングとその手法
この授業では演習問題を通して教師なし学習とクラスタリングを学びます。
クラスタリングは、データを特徴ごとにグループ化する手法で、教師なし学習の代表例です。本授業では、k-means法やウォード法などのクラスタリング手法を学び、データの構造を把握する方法について理解を深めます。
<05>次元削減と特徴抽出
この授業では演習問題を通して次元削減と特徴抽出を学びます。
次元削減は、データの情報を保持しつつ特徴量の数を減らし、モデルの計算効率向上や過学習の防止に役立ちます。本授業では、主成分分析(PCA)やt-SNEなどの手法を学び、データの最適な表現方法について理解を深めます。
<06>推奨システムとトピックモデル
この授業では演習問題を通して推奨システムとトピックモデルを学びます。
推奨システムは、ユーザーの行動やデータを基に適切な商品やサービスを提示する技術であり、協調フィルタリングやコンテンツベースフィルタリングなどの手法があります。一方、トピックモデルは文書データを潜在的なトピックに分類する手法で、潜在的ディリクレ配分法(LDA)などが活用されます。本授業では、それぞれの手法の特徴や活用例を学びます。
<07>強化学習の基本概念と差異
この授業では演習問題を通して強化学習の基本概念と教師あり・教師なし学習との違いを学びます。
強化学習は、エージェントが環境と相互作用しながら報酬を最大化するように学習する手法です。本授業では、マルコフ決定過程(MDP)、価値関数、割引率などの概念を学び、強化学習の仕組みとその応用について理解を深めます。
<08>方策と価値関数に基づくアプローチ
この授業では演習問題を通して方策と価値関数に基づくアプローチを学びます。
強化学習では、エージェントが最適な行動を学習するために方策(Policy)と価値関数(Value Function)が重要な役割を果たします。本授業では、Q学習や方策勾配法、REINFORCE、Actor-Criticといった手法を学び、それぞれの特徴や適用場面について理解を深めます。
<09>行動選択戦略とアルゴリズム
この授業では演習問題を通して行動選択戦略とアルゴリズムを学びます。
強化学習では、エージェントが最適な行動を選択するために探索と活用のバランスを考慮する必要があります。本授業では、e-greedy方策、UCB方策、バンディットアルゴリズムなどの手法を学び、それぞれの特徴や適用場面について理解を深めます。
<10>モデル評価の基礎
この授業では演習問題を通してモデル評価の基礎を学びます。
モデル評価は、機械学習モデルの性能を適切に判断し、過学習を防ぐために不可欠なプロセスです。本授業では、訓練誤差と汎化誤差の違い、交差検証の手法、過学習のリスクと対策について学び、信頼性の高いモデル選択のポイントを理解します。
<11>評価指標と性能分析
この授業では演習問題を通して評価指標と性能分析を学びます。
モデルの性能を適切に評価することは、正しい意思決定のために不可欠です。本授業では、混同行列をはじめとする正解率・適合率・再現率・F値などの指標、さらにROC曲線やAUCによるモデル評価の手法を学びます。また、回帰モデルの評価に用いられるMSE・RMSE・MAEの特徴についても理解を深めます。
<12>モデル選択と複雑性のバランス
この授業では演習問題を通してモデル選択と複雑性のバランスを学びます。
モデルの複雑さと性能のバランスを適切に取ることは、過学習を防ぎ、汎化性能を向上させる上で重要です。本授業では、AIC(赤池情報量規準)やBIC(ベイズ情報量規準)といったモデル選択の指標や、オッカムの剃刀の考え方を学び、適切なモデルを選択する方法について理解を深めます。